My notes & takeaways (14)
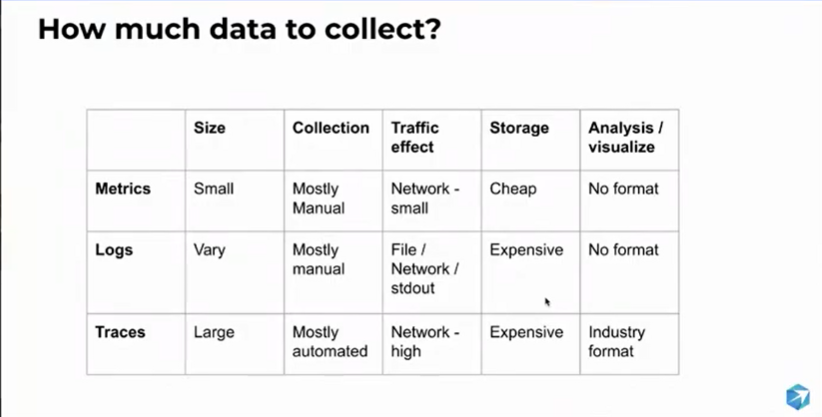 Kind of worried, as I heard “three pillars” being mentioned… but still, it’s one of the common models used.
Kind of worried, as I heard “three pillars” being mentioned… but still, it’s one of the common models used. Trace sample percentage can / should be chosen based on use case. Cost analysis can help define percentage ranges. Different percentages can be used within the use case (example: 100% of errors but 10 of the rest)
Trace sample percentage can / should be chosen based on use case. Cost analysis can help define percentage ranges. Different percentages can be used within the use case (example: 100% of errors but 10 of the rest)
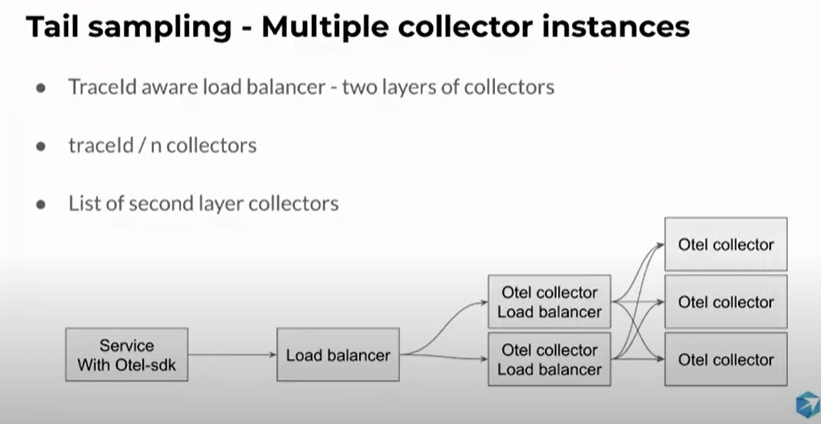
Tail sampling is a part of otel-collector-contrib_tail_sampling package / plugin, added to the collector.
When using tail sampling in the collector, samples are collected during a period of time (decision_wait), though that means it is subject to failure/trace loss if the collector fails (out of memory, etc)
Interesting conditions to choose on:
- latency
- numeric attribute
- probability
- status code
- string attributes
- rate limiting
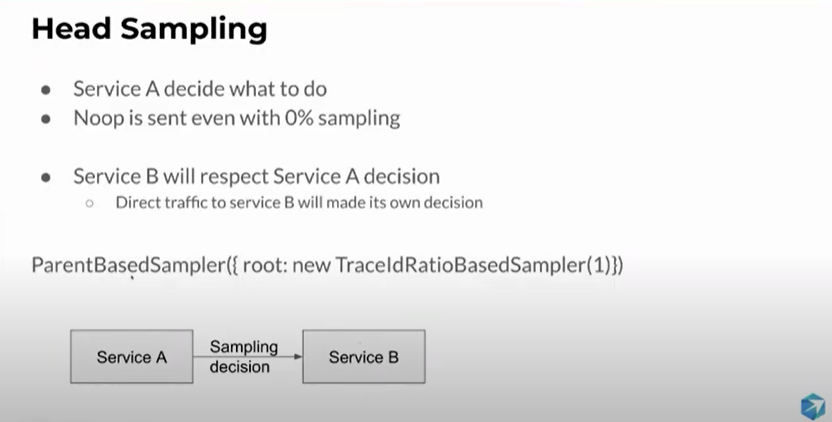 Parent Based sampler - Service B respects Service A’s decision of sampling or not.
Parent Based sampler - Service B respects Service A’s decision of sampling or not.
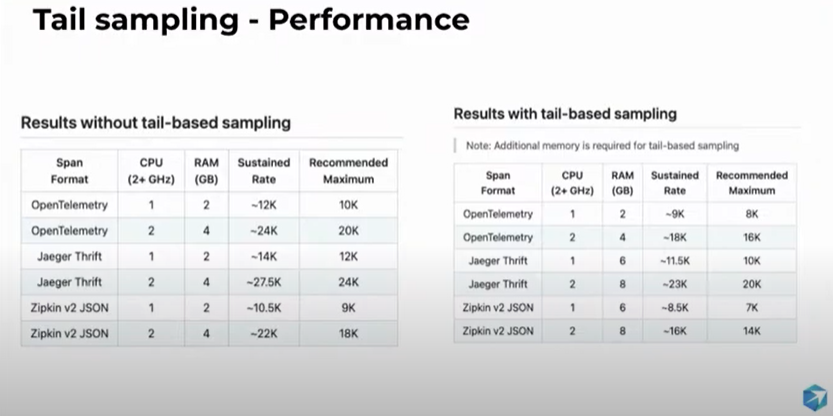 Tail based requires more memory since it needs to buffer and decide late.
Tail based requires more memory since it needs to buffer and decide late. You may need an extra layer if your target can’t handle the load.
You may need an extra layer if your target can’t handle the load. 3 metrics to calculate cost.
3 metrics to calculate cost.
