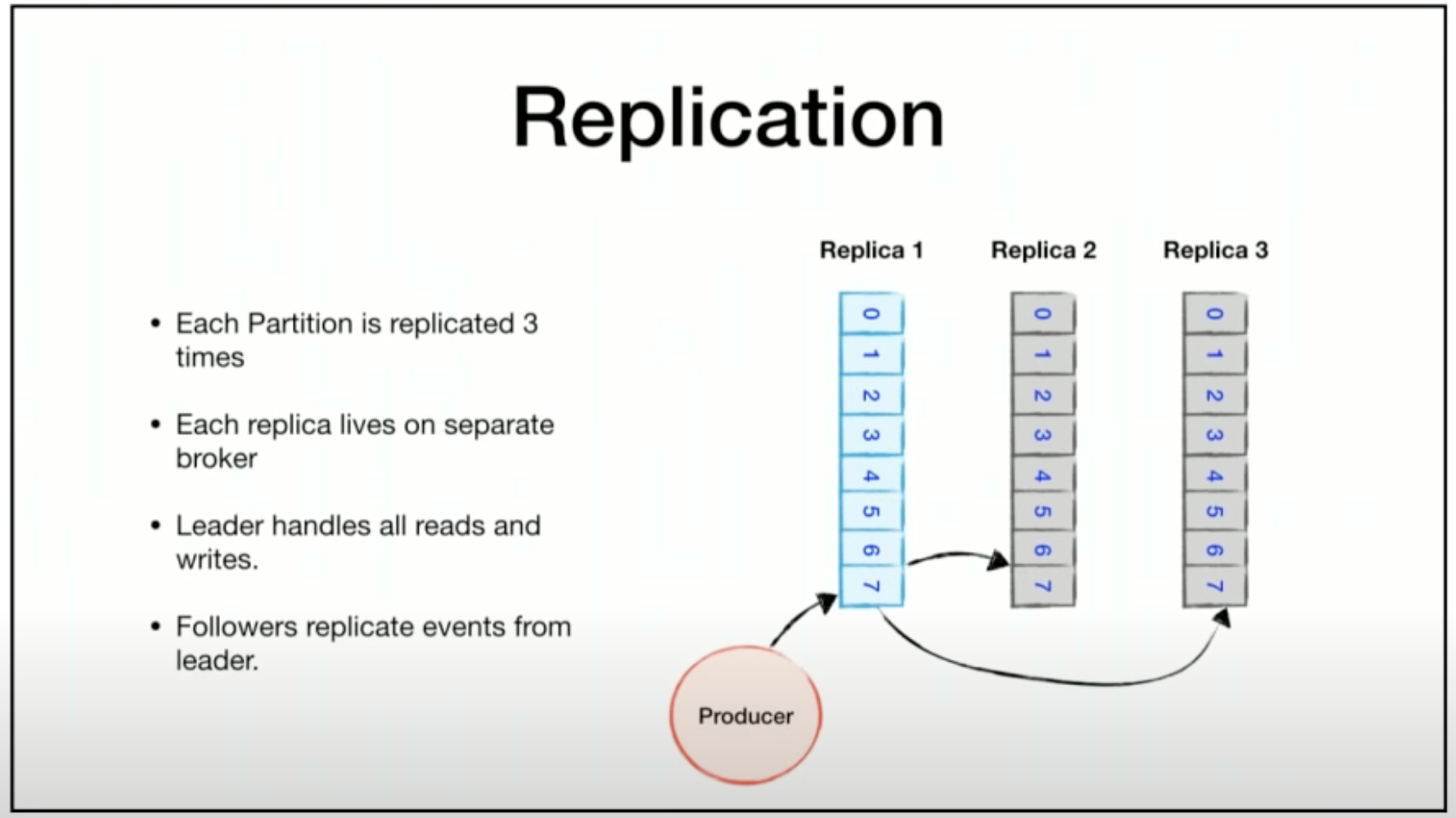
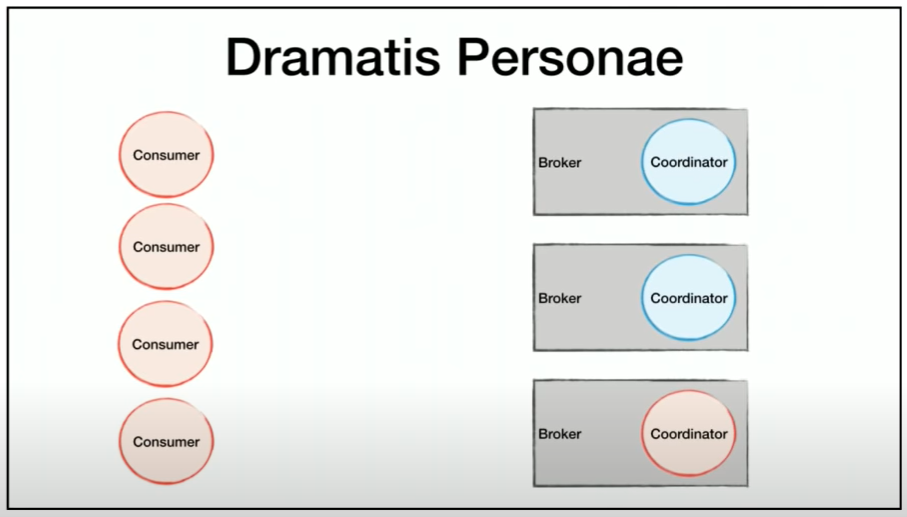
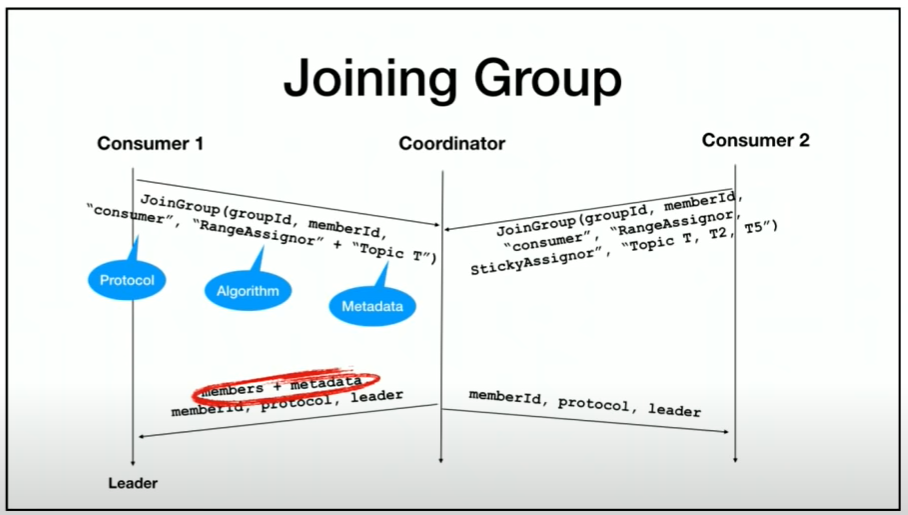
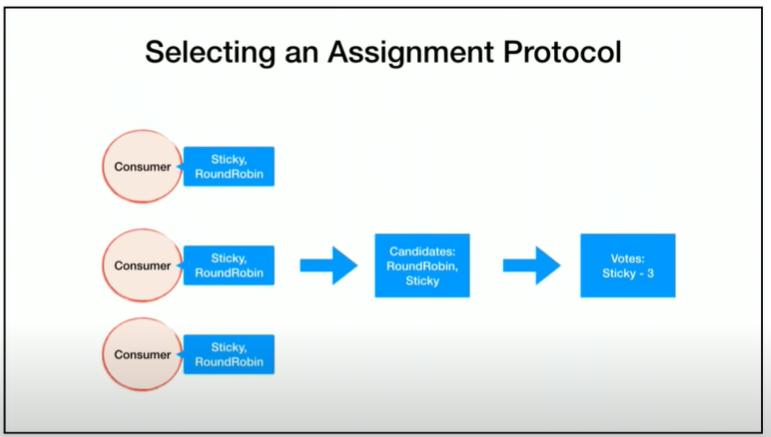
I’ve been debugging a weird and considered impossible situation on a Kafka cluster and/or consumer service. I have a multi-instance service where something occurs that causes one of the instances to get all the partitions assigned, though the partitions on the other instance do not get revoked. Theoretically, a partition can only be consumed by a single consumer in a group; in this case though, 2 consumers in the same group are consuming the same partition. This leads to concurrent processing on the same instance. Luckily, the consumers are idempotent, so they can still handle the situation, but it does generate a bunch of error events.
This clip was recommended to me by colleague Douglas, to help understand better the rebalancing protocol.