External links for the notes
I’ve been debugging a weird and considered impossible situation on a Kafka cluster and/or consumer service. I have a multi-instance service where something occurs that causes one of the instances to get all the partitions assigned, though the partitions on the other instance do not get revoked. Theoretically, a partition can only be consumed by a single consumer in a group; in this case though, 2 consumers in the same group are consuming the same partition. This leads to concurrent processing on the same instance. Luckily, the consumers are idempotent, so they can still handle the situation, but it does generate a bunch of error events.
I’m analysing this one as a follow up to Gwen Shapiro’s talk The Magical Rebalance Protocol of Apache Kafka
My notes & takeaways (12)
The Group Coordinator manages the consumer group and the consumers. This is a Kafka component that lives on the broker side. It will make one consumer the lead, and this will be responsible for computing the topic partition assignments. These are returned to the Group Coordinator which then assigns the partitions to the consumers.
An example is given
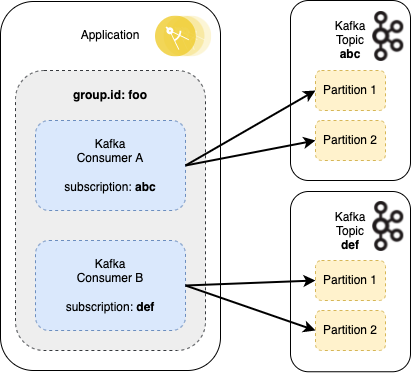
If a service has multiple consumers that subscribe to mutually exclusive topics but that share the same group.id then any rebalance triggered by any one consumer would still affect the other consumers in the group
The author gives a nice example to help follow up which matches the way I’m consuming things
In the following scenario Consumer A is subscribed to topic abc, whilst Consumer B is subscribed to topic def. They are in the same consumer group foo. If Consumer A takes too long to process a batch and times out then it is removed from the consumer group triggering a rebalance. All partition assignments in the group are revoked and reassigned, including those for Consumer B.
When Consumer A eventually completes its poll and rejoins the consumer group, a further rebalance is triggered, and again all processing stops as partitions are revoked and reassigned. It can therefore be prudent to define separate consumer groups for consumers listening to different topics. e.g. service-topic-consumer-group.
This is a possible aspect to consider - In my use case, I do configure all the topic consumption in the same service instance as the same consumer. So if a rebalance occurs, it happens against all the topics consumed based on the above info."
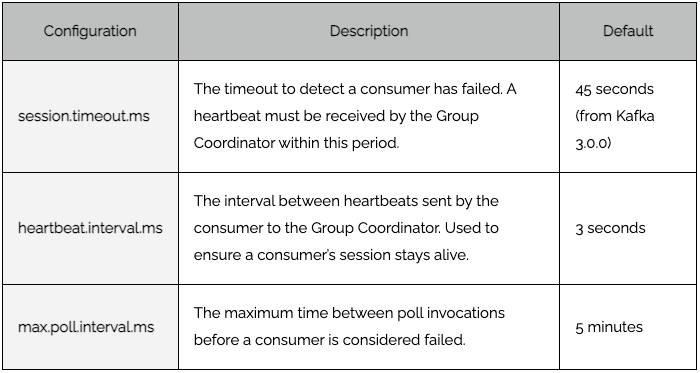
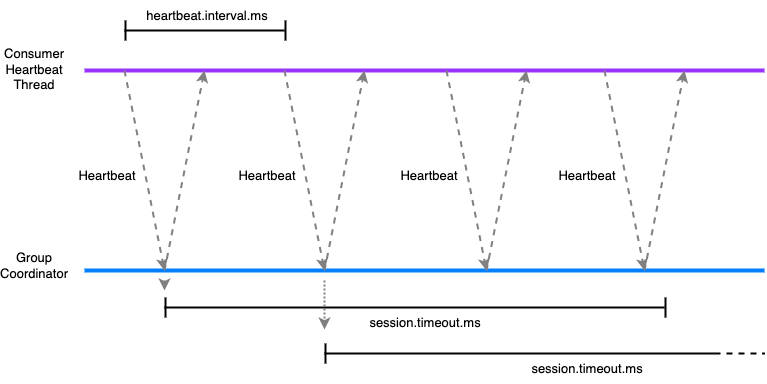
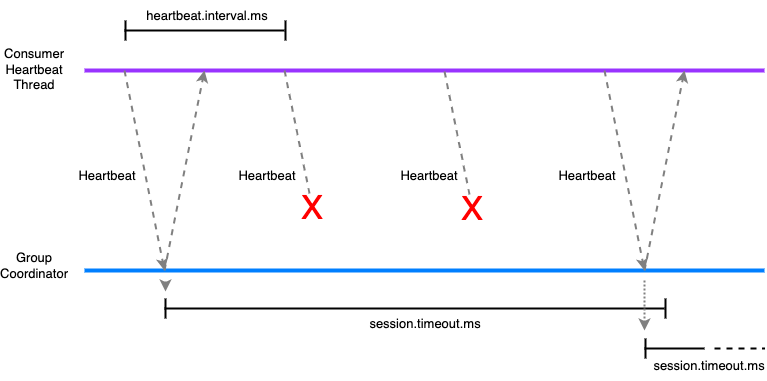 It is recommended to configure the heartbeat.interval.ms to be no more than a third of session.timeout.ms. This ensures that if a heartbeat or two are lost due for example to a transient network issue, that the consumer is not considered to have failed. In this diagram two heartbeats are lost, but the third arrives before the session has timed out, so the Group Coordinator knows the consumer is still healthy.
It is recommended to configure the heartbeat.interval.ms to be no more than a third of session.timeout.ms. This ensures that if a heartbeat or two are lost due for example to a transient network issue, that the consumer is not considered to have failed. In this diagram two heartbeats are lost, but the third arrives before the session has timed out, so the Group Coordinator knows the consumer is still healthy.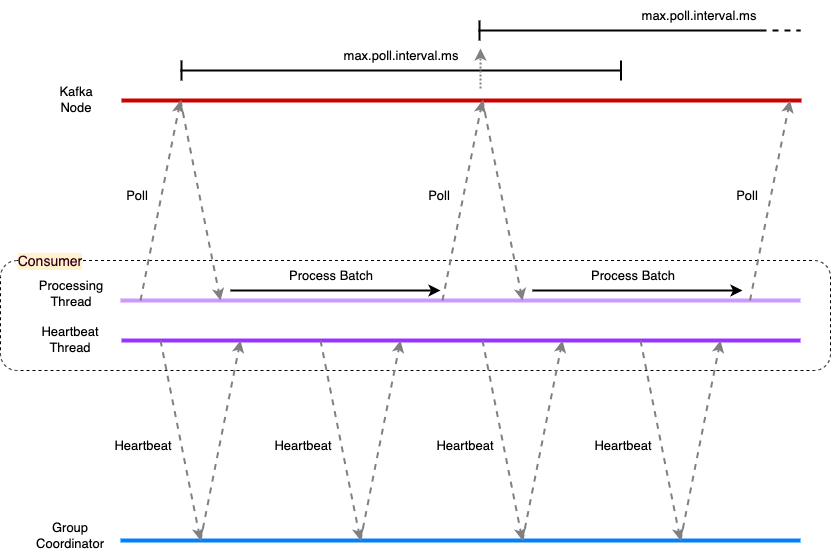 Consumer heart beating and polling. Polling is done on a different thread.
Consumer heart beating and polling. Polling is done on a different thread.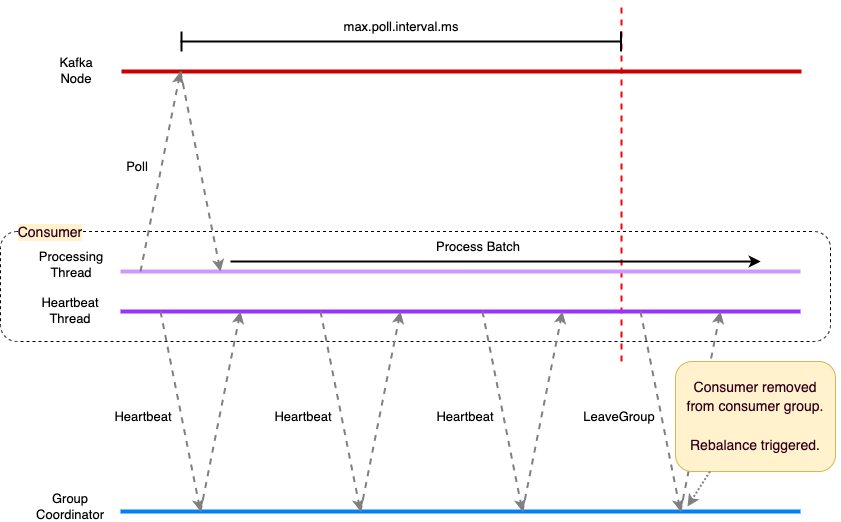
The heartbeat thread checks the status of the consumer processing, and if the max.poll.interval.ms has been exceeded between polls then rather than a heartbeat it sends a LeaveGroup request. The Group Coordinator removes the consumer from the consumer group triggering a rebalance.
Configuring the max.poll.interval.ms therefore requires careful consideration. Set it too low and the risk is that the batch of messages consumed in a single poll are not processed in time leading to rebalancing and duplicate message delivery. Set the interval too high and it means that when a consumer does fail it takes longer before the broker is aware and the consumer’s partitions are reassigned. During this processing the messages on the topic partitions assigned to the failed consumer are stuck.
There are therefore two time outs to consider that have a bearing on when a consumer is considered healthy or to have failed and be evicted from a consumer group. If the main processing thread dies, leaving the heartbeat thread still running, the failure is detected by the max.poll.interval.ms being exceeded. If the whole application dies then this will be detected by no heartbeat being received within the session.timeout.ms.
The max.poll.interval.ms is essentially the main health check for the consumer processing. However by also utilizing a heartbeat check on a separate thread it means that hard failures where the whole application has failed are detected more quickly.
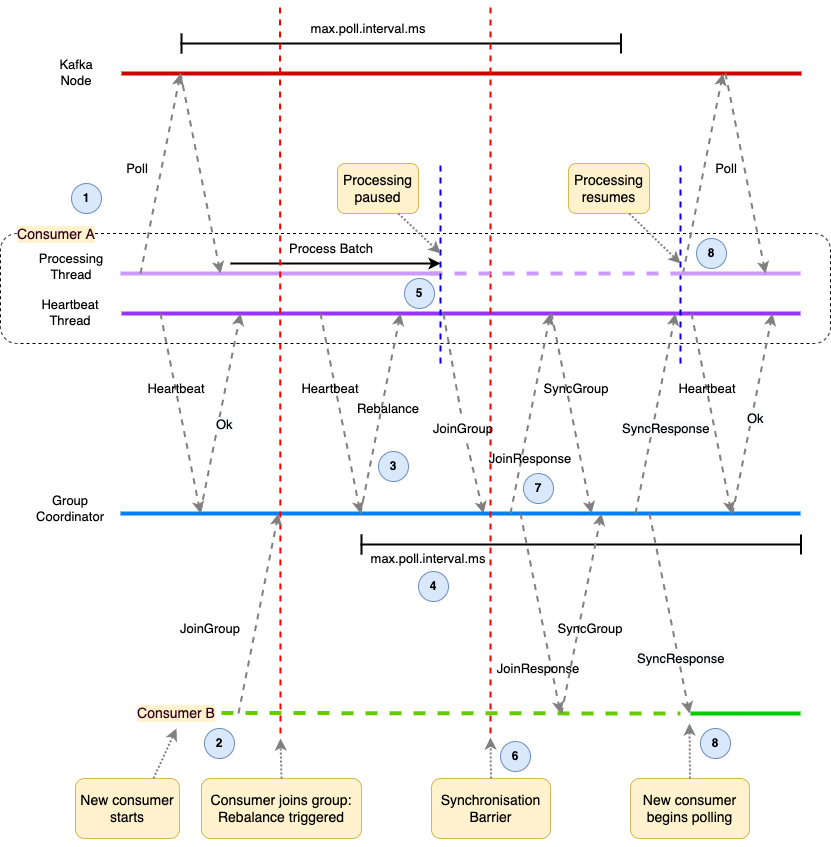
Incremental (Cooperative) Rebalance
If the impact of eager consumer group rebalances stopping message processing while they are occurring is considered too great, then an Incremental Rebalance strategy could be adopted. Existing consumers that have been notified by the Group Coordinator that a rebalance is underway do not stop processing. Instead rebalancing occurs over two phases.
Only those partitions that need to be reassigned are revoked. The other partitions are constantly owned by their consumers with no interruption to consumption of their messages.
Incremental Rebalance takes two rounds of rebalancing to complete, so results in longer overall latency. However the impact of the rebalance is less severe to overall message processing.
Incremental Rebalance is configured by applying a CooperativeStickyAssignor to the consumer’s partition.assignment.strategy setting.
CooperativeStickyAssignor is at play in my case. I can see revocations sometimes. But in the case of the error, the revoke messages are missing.
Static Group Membership
With the default rebalance protocol when a consumer starts it is assigned a new member.id (which is an internal Id in the Group Coordinator) irrespective of whether it is an existing consumer that has just restarted. Any consumer starting triggers a rebalance, and is assigned a new member.id. With this protocol the consumer cannot be re-identified as the same.
With static group membership, the consumer will be attributed the samemember.id, even if it just restarts, based on it’s group.instance.id.
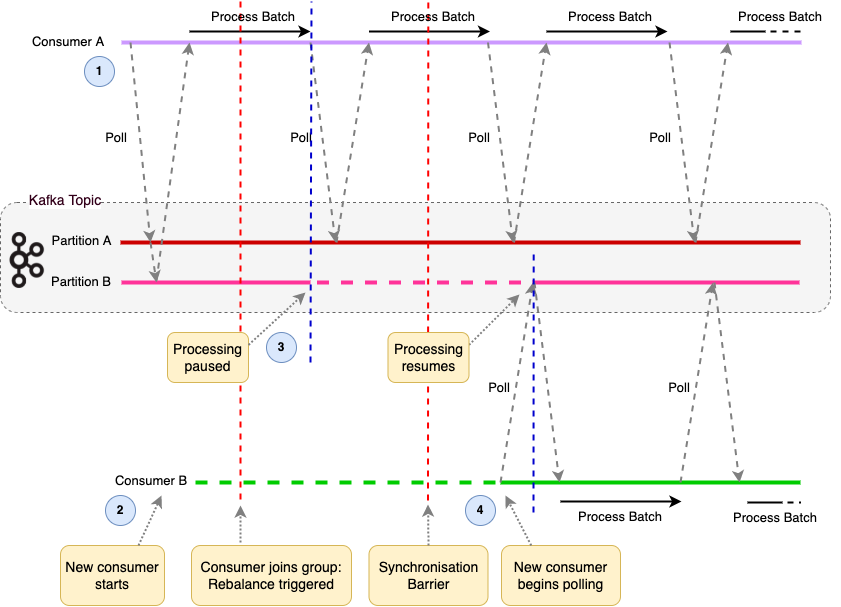
The partitions that were assigned to that consumer are reassigned to it and processing of messages from those partitions now resumes. Meanwhile there was no interruption to the processing of messages on partitions assigned to other consumers.
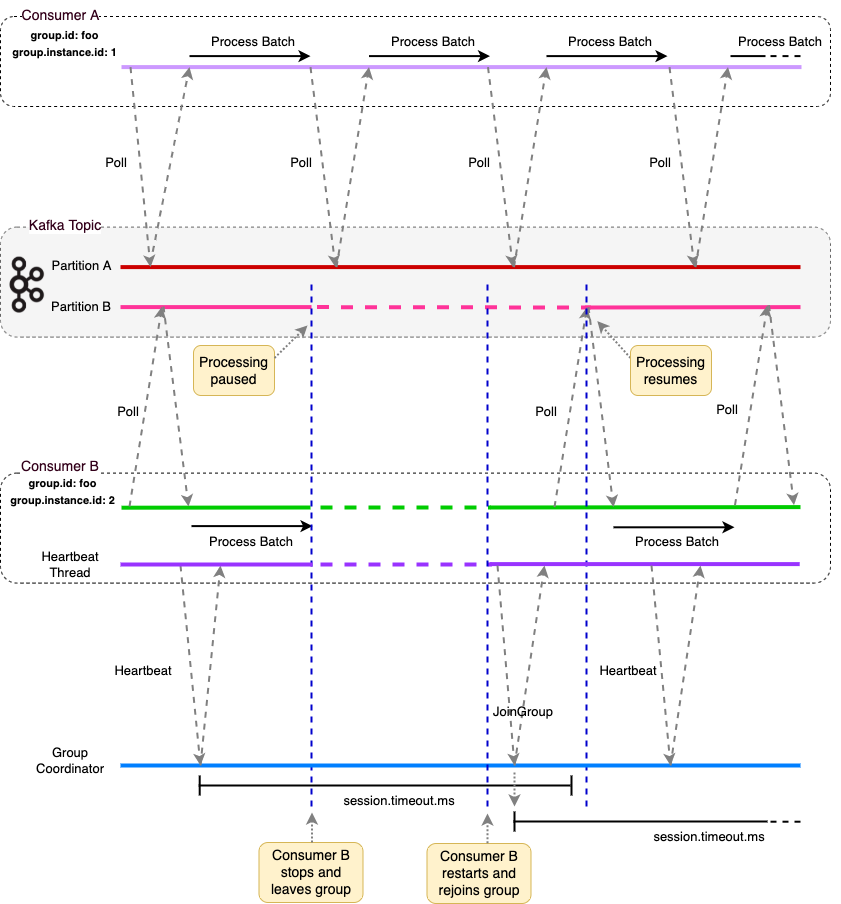
The following diagram demonstrates static group membership. Two consumers belong to the same consumer group and have distinct group.instance.id values assigned. They are polling a partition each from the same topic. Consumer B stops and leaves the group, however a rebalance is not immediately triggered. The consumer rejoins the group before the session.timeout.ms times out and is reassigned its partition, ensuring no rebalance is required. This feature could be utilized for example by tieing the Id of the Kubernetes pod that an application is running in to the application consumer’s group.instance.id. If the pod dies and restarts then the Group Coordinator will recognize the consumer as the group.instance.id will be the same, and the potentially costly rebalance is avoided. For a consumer with static group membership it does not send a LeaveGroup request when it leaves a group (or indeed fails). Rather it stops heartbeating and remains in the group until the session.timeout.ms has been exceeded and is removed from the group by the Group Coordinator.
can’t see this as a problem in my current issue…
On Rebalance Risks
Duplicate messages - A consumer that has exceeded its time out and is considered failed could still be processing the messages it has polled, and that processing could complete successfully. However its consumer offsets write will be rejected as the consumer group rebalance increments the generation Id, and any writes with the previous generation Id are rejected. Meanwhile a new consumer instance is assigned the topic partitions in a rebalance and this consumes and processes the same messages. It is always important to be aware that the application may receive duplicate messages and it must cater for these, if necessary, as required.
Rebalance Storms - Rebalance does not complete until all existing consumers have either rejoined or exceeded the max.poll.interval.ms. If a consumer does indeed exceed the max.poll.interval.ms before it again polls as it is taking longer than expected to process its last batch of messages then when it does complete it will request to rejoin the group, triggering another rebalance. If the cause of the rebalance is for example due to slow responding downstream services that are affecting all consumers the upshot can be rebalance after rebalance being triggered as consumers are continually evicted and then rejoin, a ‘rebalance storm’. Static Group Membership and Incremental rebalancing can of course assist with this but whatever strategies are in place care must be taken with the rebalance configurations.
Could use of
autocommit reflect in the duplicate message processing? Even though one of the consumers is considered failed, it can still process messages it has polled. This doesn’t explain how it keeps getting messages long after. Fortunately, consumer is idempotent and can handle this.